The Reproducibility Problem in Machine Learning
Most ML research cannot be reproduced.because the culture and infrastructure around research make reproducibility an afterthought.
- tags
- #Generalist-Notes #Series #Ai-and-Tech #Psychology #Learning
- published
- reading time
- 5 minutes
Reproducibility is the corner stone of science
Somewhere between building a model and publishing the results, something gets lost. not the results themselves, those make it into the paper. what gets lost is everything that would allow someone else to arrive at the same place.
This is the reproducibility problem in machine learning, and it is more widespread than most people admit.
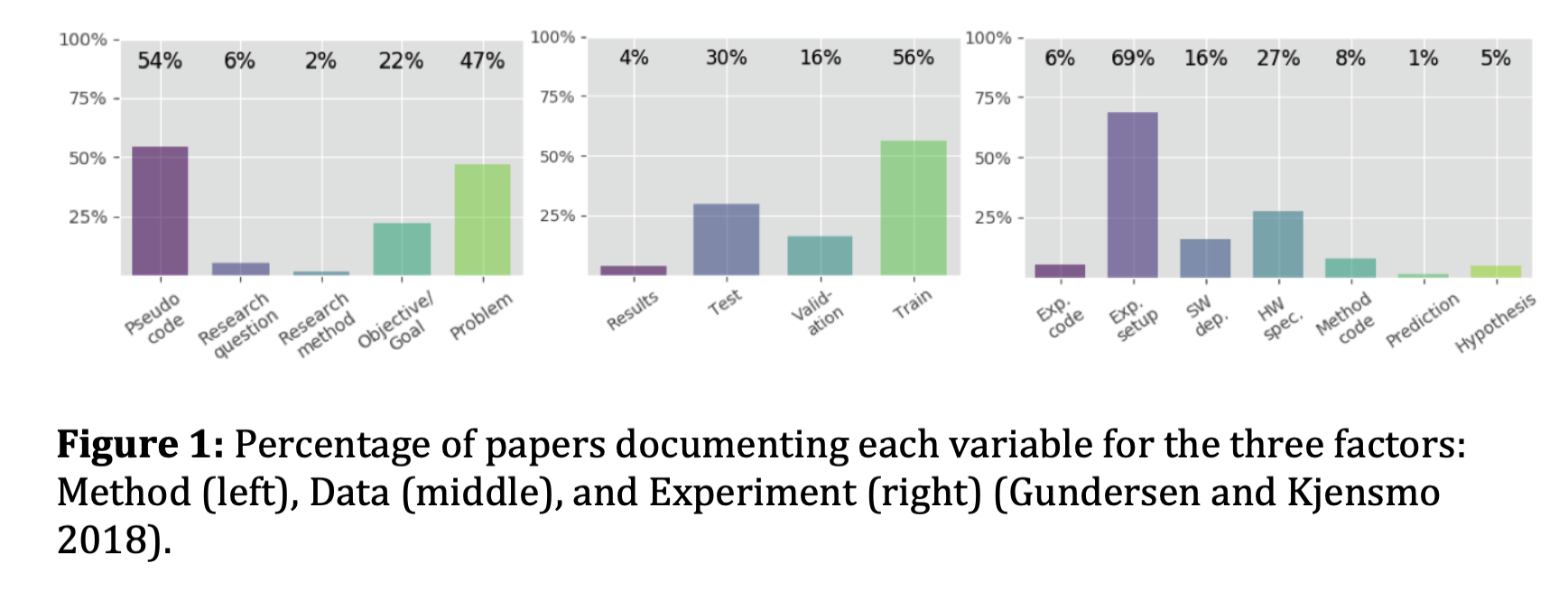
In 2016, the journal Nature reported that around 70% of researchers had failed to reproduce another researcher’s results , and 50% had failed to reproduce their own. machine learning is no exception. a study that analyzed 400 papers from top AI conferences found that only 6% shared code, roughly 33% shared test data, and 54% shared nothing more than a pseudocode summary of their algorithm. not the environment. not the hyperparameters. not the exact version of the library that made it work. just a rough sketch of the idea.
Research and Artifacts
Research, in the way most of us were taught to think about it, follows a clean sequence. you start with a belief or observation, form a hypothesis, make a prediction, run an experiment, collect results, and interpret them. the arrows go one direction. the process is transparent and repeatable.
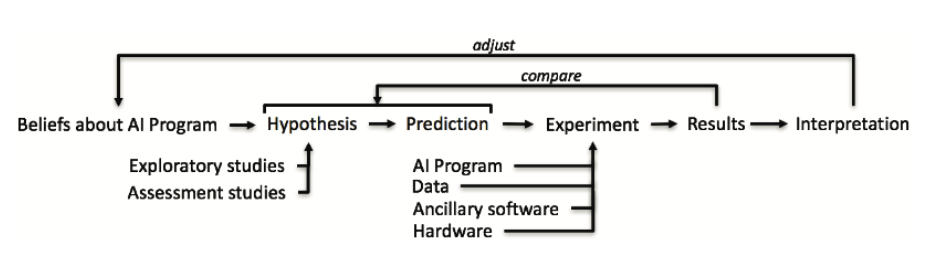 Figure 0.1 Research Life Cycle
Figure 0.1 Research Life Cycle
The reality is that the experiment step in that diagram is fed by four inputs that almost never get fully documented: the AI program itself, the data it trained on, the ancillary software, every library, framework, and dependency, and the hardware the whole thing ran on. change any one of those, and your results may not survive the move. the feedback arrows at the top, adjust and compare, assume you can get back to the same starting point. most of the time in ML research, you cannot. not because the experiment was wrong, but because no one recorded what the experiment actually was.
What reproducibility actually means
Reproducing a result is not just running someone else’s code and getting the same number. it is being able to reconstruct the exact conditions under which an experiment was conducted, the data, the environment, the dependencies, the random seeds, the sequence of decisions, and arrive at the same conclusions. it is the difference between a finding and a fact.
The scientific method has always required this. you form a hypothesis, collect data, experiment, analyze, and conclude. the whole system depends on the assumption that if someone else follows the same process, they arrive at the same place. when that assumption breaks down, the entire chain of knowledge built on top of that result becomes unreliable.
In ML, that chain is long. papers build on papers. models are pertained on datasets that trained on other datasets. if a foundational result cannot be reproduced, everything built on it is standing on uncertain ground.
Why it keeps happening
The problem is not that researchers are careless. most of them are working at the edge of what’s understood, moving fast, under pressure to publish. the problem is structural.
Academic research culture is optimized for publishing findings, not for packaging them. a researcher who spends two extra weeks making their code clean, their environment versioned, and their artifacts shareable is spending time that doesn’t show up anywhere on their CV. there is no incentive built into the system for it. The specific failure points are predictable. dependency drift, where a result depends on a specific version of a library that was never documented, and by the time someone tries to reproduce it, that version no longer behaves the same way. poor experiment tracking, where the notebook that produced the final result is the seventh notebook in a folder called “experiments_final_v3_actually_final”, and no one, including the author, can trace which decisions led where. and artifact sharing, where the trained model, the processed dataset, the intermediate outputs that made the result possible, simply weren’t saved or shared.
 code quality in academia over time
code quality in academia over time
I’ve seen this from the inside. working on reproducibility of machine learning systems , and before that at AirQo as an ML engineer, the gap between building a model and being able to hand it to someone else in a trustworthy state is much wider than it looks from the outside. what gets you to a result in a notebook is rarely what you’d want to give someone to reproduce it.
What industry figured out that academia hasn’t
Outside of academic research, this problem was largely solved, or at least seriously addressed, through MLOps. the term appeared around 2015 and describes a set of practices and tools that treat a machine learning system with the same engineering discipline as any production software: version control for data and code, experiment tracking, containerization, artifact registries, automated testing. in industry, if a model cannot be reproduced in a new environment, that is a production incident. it gets fixed.
In academia, the same failure is often just a footnote in a follow up paper that couldn’t replicate the original results. The ACM survey on robustness in MLOps frames this clearly: trustworthy machine learning in production requires reproducibility as a foundation, not an afterthought. the tools exist. the practices are understood. what’s missing is the bridge between how industry builds ML systems and how academia runs ML experiments.
That bridge is what I’ve been thinking about. not as an abstract problem, but as something I’ve personally run into, in competitions, in production, and now in research. the solution is not to make researchers into software engineers. it is to make the right practices the path of least resistance, no friction, so that reproducibility happens by default rather than by exceptional effort.
I’ll write more about what that looks like in practice. for now, the problem is worth sitting with: we are building a field on results that, in many cases, we cannot verify.